
















Adventures With Open Source ETL
One of the greatest benefits I get from working at Kaltura, is the opportunity to work with some of the greatest open source projects out there. I’ve written about Kaltura’s data warehouse (DWH), powering the entire analytics side of Kaltura’s products and services, and I promised I’d go into more details about the technology that makes the...
![]() One of the greatest benefits I get from working at Kaltura, is the opportunity to work with some of the greatest open source projects out there. I’ve written about Kaltura’s data warehouse (DWH), powering the entire analytics side of Kaltura’s products and services, and I promised I’d go into more details about the technology that makes the data crunching engine turn.
One of the greatest benefits I get from working at Kaltura, is the opportunity to work with some of the greatest open source projects out there. I’ve written about Kaltura’s data warehouse (DWH), powering the entire analytics side of Kaltura’s products and services, and I promised I’d go into more details about the technology that makes the data crunching engine turn.
A bit of Data Crunching
Almost all data warehouse and analytic systems use a process called ETL, or Extract, Transform & Load. At Kaltura, we use these steps to describe the following actions (and we add one of our own):
- Extract – fetch the source files from the various sources, unzip, split and sort them into process cycles.
- Transform – filter invalid data points and organize the data into the table schema described in this post. The output of this step is a file that can be loaded quickly into the database.
- Load – load the temporary file into the database.
- Aggregate – after the data is loaded, we aggregate the new data into a set of aggregation tables. These aggregation tables allow us to provide snappy analytic reports in our KMC.
To manage the entire process we use a tool called Pentaho Data Integration (PDI, a.k.a. Kettle).
A GUI for Data Manipulation
Kettle is a suite of tools designed for data manipulation. It has everything but the kitchen sink. It’s a data processing double feature in one ticket.
The first tool is Kitchen, a command line tool for running Kettle jobs and transformations. This is the tool that runs the data processing out of our ETL servers. The second is Spoon. Spoon is a GUI for data manipulation. It’s the way we design and implement our processing requirements.
Here’s a screenshot from Spoon:
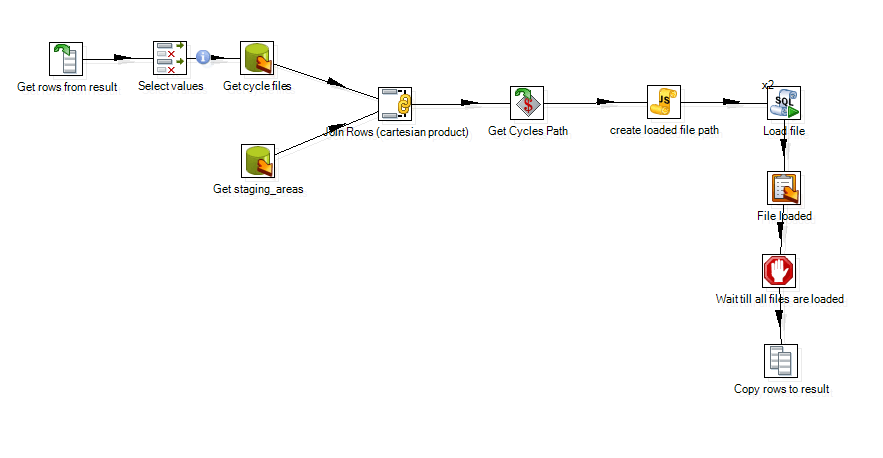
The way Kettle works is by streaming data rows through a series of pipes and steps. Each pipe is a buffer between two steps that can help buffer rows. Each icon is a processing step, a thread in the system, specialized in one thing. Data flows through the process as fast as it can. In the picture above you can clearly see data input from two tables, combined and then streamed through some other steps. It’s quite easy to read and, once you learn how to work with it, also very simple to create and expand.
An Extensible System
One of the best things about Kettle is how flexible it is. At Kaltura, we have created several such custom steps to help us perform better. We have also developed a set of generic data transformations that help us manage data flow. During the past year we have worked hard to make it as easy as possible to add new data sources and aggregations, so that we can answer our customers’ requirements faster and faster, and the Pentaho team has built a tool that’s really geared towards extensions.
There are many great data sources for Kettle, my personal favorite being Adventures With Open Source BI. If you want to learn more about Kettle and ETL, it’s a great place to look for Kettle receipts and tips.
Was this post useful?
Thank you for your feedback!